


要想做反爬虫,我们首先需要知道如何写个简单的爬虫。
通常编写爬虫需要经过这么几个过程:
• 分析页面请求格式
• 创建合适的http请求
• 批量发送http请求,获取数据
举个例子,直接查看携程生产url。在详情页点击“确定”按钮,会加载价格。假设价格是你想要的,那么抓出网络请求之后,哪个请求才是你想要的结果呢? 你只需要用根据网络传输数据量进行倒序排列即可。因为其他的迷惑性的url再多再复杂,开发人员也不会舍得加数据量给他。

代码:
import requests
def download_page(url):
headers={
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.80 Safari/537.36'
}
data = requests.get(url,headers=headers)
return data
if __name__ == '__main__':
url = 'https://m.ctrip.com/restapi/soa2/21881/json/HotelSearch?testab=5b9a651b08c1069815c5af78f8b2bf6df9dd42a6129be5784bb096315494619a'
download_page(url)
高级爬虫
那么爬虫进阶应该如何做呢?通常所谓的进阶有以下几种:
分布式爬虫
Python默认情况下,我们使用scrapy框架进行爬虫时使用的是单机爬虫,就是说它只能在一台电脑上运行,因为爬虫调度器当中的队列queue去重和set集合都只能在本机上创建的,其他电脑无法访问另外一台电脑上的内存和内容。
分布式爬虫实现了多台电脑使用一个共同的爬虫程序,它可以同时将爬虫任务部署到多台电脑上运行,这样可以提高爬虫速度,实现分布式爬虫。
首先就需要配置安装redis和scrapy-redis,而scrapy-redis是一个基于redis数据库的scrapy组件,它提供了四种组件,通过它,可以快速实现简单分布式爬虫程序。
四种scrapy-redis组件:
Scheduler(调度):Scrapy改造了python本来的collection.deque(双向队列)形成了自己Scrapy queue,而scrapy-redis 的解决是把这个Scrapy queue换成redis数据库,从同一个redis-server存放要爬取的request,便能让多个spider去同一个数据库里读取。Scheduler负责对新的request进行入列操作(加入Scrapy queue),取出下一个要爬取的request(从Scrapy queue中取出)等操作。
Duplication Filter(去重):Scrapy中用集合实现这个request去重功能,Scrapy中把已经发送的request指纹放入到一个集合中,把下一个request的指纹拿到集合中比对,如果该指纹存在于集合中,说明这个request发送过了,如果没有则继续操作。
Item Pipline(管道):引擎将(Spider返回的)爬取到的Item给Item Pipeline,scrapy-redis 的Item Pipeline将爬取到的 Item 存⼊redis的 items queue
Base Spider(爬虫):不再使用scrapy原有的Spider类,重写的RedisSpider继承了Spider和RedisMixin这两个类,RedisMixin是用来从redis读取url的类。
工作原理:
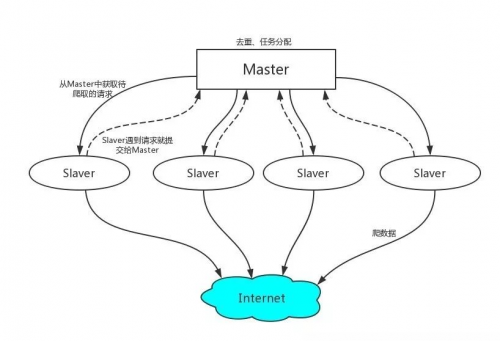
1、首先Slaver端从Master端拿任务(Request、url)进行数据抓取,Slaver抓取数据的同时,产生新任务的Request便提交给 Master 处理;
2、Master端只有一个Redis数据库,负责将未处理的Request去重和任务分配,将处理后的Request加入待爬队列,并且存储爬取的数据。
模拟JavaScript
模拟javascript,抓取动态网页,是进阶技巧。但是其实这只是个很简单的功能。因为,如果对方没有反爬虫,你完全可以直接抓ajax本身,而无需关心js怎么处理的。如果对方有反爬虫,那么javascript必然十分复杂,重点在于分析,而不仅仅是简单的模拟。
PhantomJs或者selenium
以上的用来做自动测试的,结果因为效果很好,很多人拿来做爬虫。但是这个东西有个硬伤,就是:效率。占用资源比较多,但是爬取效果很好。
总结:越是低级的爬虫,越容易被封锁,但是性能好,成本低。越是高级的爬虫,越难被封锁,但是性能低,成本也越高。
当成本高到一定程度,我们就可以无需再对爬虫进行封锁。经济学上有个词叫边际效应。付出成本高到一定程度,收益就不是很多了。














 京公网安备 11010802030320号
京公网安备 11010802030320号