


很多人都在怀疑参加千锋大数据工程师培训学习六个月真的就能拿到高薪吗?很多人都抱有这样的疑问,而这里的“很多人”也包括我自己。就业的压力,工作的不顺,最终,我抱着试试看的心态来到了千锋参加大数据培训。一个月的Javase的学习已经划上了句号,从最开始的茫然不适,到此时此刻,心情感慨万千,这里良好的学习氛围,舒适的学习环境以及努力拼搏的每一位同学都深深的感染了我。对于一个大数据零基础的我,压力与动力并存。每天的学习内容颇多,也有很多难点需要克服,整个人忙成了钟表的秒针,时时刻刻都在向前奔跑。身心都感觉十分疲惫,但是钻研过后,难题一朝而解时的痛快,显示器前通篇的代码,甚至幻听下耳旁不曾停息的敲键声,一切似乎都格外让人振奋,你的努力都是可以直观看到听到的。这就是一个刻苦攻坚的过程,酸甜苦辣皆有。
千锋大数据培训机构它给我带来的额不是大学那种颓废的感觉,更多的是一种朝气,身边的每个人时时刻刻都在告诉你,你不努力,你就有可能被这个社会所抛弃,为了高薪,总之,既来之,则安之。接下来说说最近学习的知识点,也记下自己分秒努力的过程。
关于shuffle 阶段
Shuffle过程包括在Map和Reduce两端中。 在Map端的shuffle过程是对Map的结果进行分区(partition)、排序(sort)和分割(spill),然后将属于同一个划分的输出合并在一起(merge)并写在硬盘上,同时按照不同的划分将结果发送给对应的Reduce(Map输出的划分与Reduce的对应关系由JobTracker确定)。 Reduce端又会将各个Map送来的属于同一个划分的输出进行合并(merge),然后对merge的结果进行排序,最后交给Reduce处理。通俗的讲,就是对Map输出结果先进行分区(partition),如“aaa”经过Partitioner后返回0,也就是这对值应当交由第一个reducer来处理。接下来,需要将数据写入内存缓冲区中,缓冲区的作用是批量收集map结果,减少磁盘IO的影响。我们的key/value对以及Partition的结果都会被写入缓冲区。当然写入之前,key与value值都会被序列化成字节数组。这个内存缓冲区是有大小限制的,默认是100MB。当map task的输出结果很多时,需要在一定条件下将缓冲区中的数据临时写入磁盘,然后重新利用这块缓冲区。这个从内存往磁盘写数据的过程被称为Spill。Spill可以认为是一个包括Sort和Combiner(Combiner是可选的,用户如果定义就有)的过程。先进行sort可以把缓冲区中一段范围key的数据排在一起,(如果数据多的时候,多次刷新往内存缓冲区中写入的数据可能会有属于相同范围的key,也就是说,多个spill文件中可能会有统一范围的key,这就是需要下面Map端merge的原因),这里有点绕,具体的介绍可以看下面的详细过程,执行过sort之后,如果用户定义了combiner就会执行combine,然后执行merge操作,接着就是Reduce端。
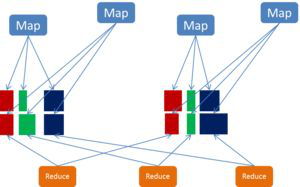
一、Map端的shuffle
Map端会处理输入数据并产生中间结果,这个中间结果会写到本地磁盘,而不是HDFS。每个Map的输出会先写到内存缓冲区中,当写入的数据达到设定的阈值时,系统将会启动一个线程将缓冲区的数据写到磁盘,这个过程叫做spill。
在spill写入之前,会先进行二次排序,首先根据数据所属的partition进行排序,然后每个partition中的数据再按key来排序。partition的目是将记录划分到不同的Reducer上去,以期望能够达到负载均衡,以后的Reducer就会根据partition来读取自己对应的数据。接着运行combiner(如果设置了的话),combiner的本质也是一个Reducer,其目的是对将要写入到磁盘上的文件先进行一次处理,这样,写入到磁盘的数据量就会减少。最后将数据写到本地磁盘产生spill文件(spill文件保存在{mapred.local.dir}指定的目录中,Map任务结束后就会被删除)。
最后,每个Map任务可能产生多个spill文件,在每个Map任务完成前,会通过多路归并算法将这些spill文件归并成一个文件。至此,Map的shuffle过程就结束了。
二、Reduce端的shuffle
Reduce端的shuffle主要包括三个阶段,copy、sort(merge)和reduce。
首先要将Map端产生的输出文件拷贝到Reduce端,但每个Reducer如何知道自己应该处理哪些数据呢?因为Map端进行partition的时候,实际上就相当于指定了每个Reducer要处理的数据(partition就对应了Reducer),所以Reducer在拷贝数据的时候只需拷贝与自己对应的partition中的数据即可。每个Reducer会处理一个或者多个partition,但需要先将自己对应的partition中的数据从每个Map的输出结果中拷贝过来。
接下来就是sort阶段,也成为merge阶段,因为这个阶段的主要工作是执行了归并排序。从Map端拷贝到Reduce端的数据都是有序的,所以很适合归并排序。最终在Reduce端生成一个较大的文件作为Reduce的输入。
最后就是Reduce过程了,在这个过程中产生了最终的输出结果,并将其写到HDFS上。
人在努力钻研一件事情的时候,时间总是飞快,一转眼间,已经走过了一个多月的时光,听前辈们说,后面的学习内容会更加的复杂,难度也会加大,心情很是忐忑,但是却也按捺不住内心的兴奋,有认真负责的老师,有一起披星戴月努力前行的战友,毫无疑问,课程结束之时,我们一定会取得这场战役的胜利!
学习大数据开发,可以参考千锋提供的大数据学习路线,该学习路线提供完整的大数据开发知识体系,内容包含Linux&&Hadoop生态体系、大数据计算框架体系、云计算体系、机器学习&&深度学习。根据千锋提供的大数据学习路线图可以让你对学习大数据需要掌握的知识有个清晰的了解,并快速入门大数据开发。


















 京公网安备 11010802030320号
京公网安备 11010802030320号